Reward Decoupling for Multi-Agent RL
Multi-agent reinforcement learning (MARL) has achieved super-human performance on many complex sequential decision-making problems, such as DOTA 2, Starcraft II, and capture the flag. These impressive results, however, come at an immense cost: often, they require millions, if not billions, of time-consuming environmental interactions, and therefore can only be run on high-cost compute clusters.
The credit assignment problem contributes to the computational difficulties that plague large-scale MARL algorithms; as the number of agents involved in learning increases, so too does the difficulty of assessing any individual agent’s contribution to overall group success. While credit assignment already challenges reinforcement learning (RL), it is particularly prominent in large-scale cooperative MARL, because, unlike problems in which each agent can act greedily to optimize its own reward, all agents must maximize the total reward earned by the entire group. Therefore, agents must not only consider how their actions influence their own rewards, but also the rewards of every other agent in the group.
A popular class of approaches for MARL are policy-gradient methods, which also suffer from the credit assignment problem. Recent work in improving policy-gradient methods took the approach of developing concepts which were then used to extend the original actor-critic algorithm. These extensions include counterfactual multi-agent policy gradients (COMA), multi-agent game abstraction via graph attention neural networks (G2ANet), and our previous work on partial reward decoupling (PRD). The contribution of our ongoing work is to develop the machinery necessary for applying PRD to a state-of-the-art multi-agent policy-gradient method, multi-agent PPO (MAPPO).
PRD simplifies credit assignment by decomposing large cooperative multi-agent problems into smaller decoupled subproblems involving subsets of agents. PRD was applied to the actor-critic algorithm. Meanwhile, significant progress has been made towards improving the data efficiency of policy-gradient algorithms. Most notably, trust-region policy optimization (TRPO) and proximal policy optimization (PPO) improve the data efficiency of actor-critic algorithms by enabling a given batch of on-policy data to be re-used for many gradient updates. PPO, in particular, has demonstrated strong performance in multi-agent settings. However, we argue that because PPO still relies on stochastic advantage estimates, it still suffers from the credit assignment problem, and can therefore be improved by incorporating advanced credit assignment strategies.
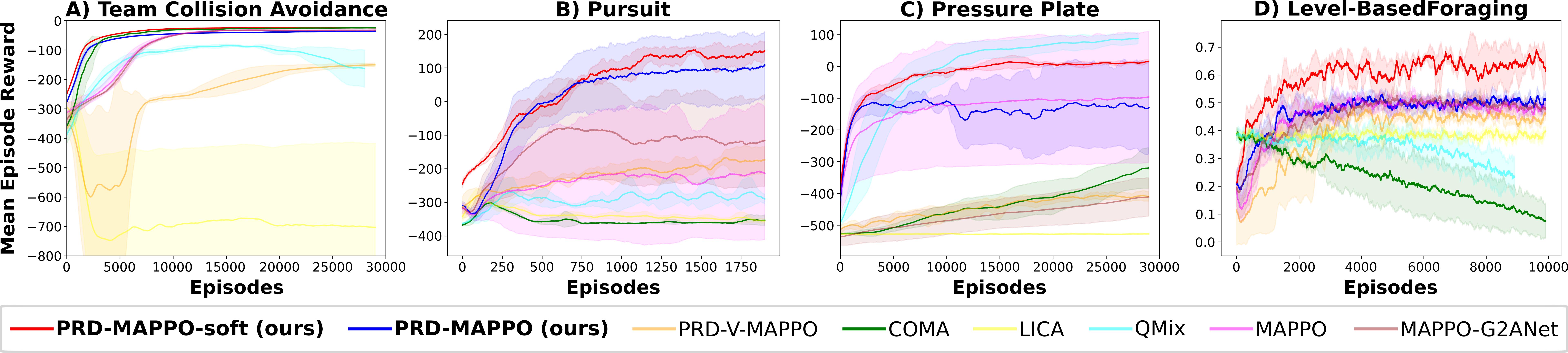
So far, we have begun to demonstrate how PRD can be leveraged within the learning update of PPO, to eliminate contributions from agents that are inconsequential to the agent’s learning update. We refer to this approach as PRD multi-agent PPO (PRD-MAPPO). We’ve found find that PRD-MAPPO yields significant improvements in learning efficiency and asymptotic performance on a diverse set of benchmarks, compared to MAPPO, and outperforms several existing state-of-the-art MARL algorithms. We additionally have developed modifications to our original PRD formulation that allows learning updates to be accelerated from quadratic time to linear time.
If you are interested in this project, or related areas in reinforcement learning, please contact Ben Freed (bfreed@andrew.cmu.edu).
[1] Freed, Benjamin, et al. “Learning Cooperative Multi-Agent Policies With Partial Reward Decoupling.” IEEE Robotics and Automation Letters 7.2 (2021): 890-897.


